 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniAudio-Token: Empowering Semantic Speech Tokenizers with General Audio Perception
May 29, 2026Semantic speech tokenizers have become a widely used interface for Audio-LLMs, owing to their compact single-codebook design and strong linguistic alignment. However, their focus on linguistic abstraction induces acoustic blindness, limiting their applicability beyond speech-centric tasks. We propose UniAudio-Token, a framework that empowers semantic tokenizers with general audio perception without compromising speech ability. Instead of altering the semantic paradigm, UniAudio-Token mitigates its information loss through two key innovations: (1) Semantic-Acoustic Primitives (SAP) provide structured supervision by decomposing audio into linguistic content, vocal attributes, and auditory-scene primitives; and (2) Semantic-Acoustic Equilibrium (SAE) introduces a content-aware gating mechanism that adaptively restores fine-grained acoustic details from shallow layers. Extensive evaluations show that UniAudio-Token learns comprehensive universal representations while preserving high-fidelity speech generation. When integrated with downstream LLMs, it outperforms all single-codebook baseline tokenizers on both understanding and generation tasks, effectively serving as a unified audio interface. We publicly release all our code, including training and inference scripts, together with the model checkpoints at https://github.com/Tencent/Universal_Audio_Tokenizer.
DiffSpot: Can VLMs Spot Fine-Grained Visual Differences in Web Interfaces?
May 28, 2026Vision-language models (VLMs) have made strong progress on high-level image-text alignment, yet their ability to perceive subtle visual differences remains limited. We study this problem in rendered web interfaces, where localized visual changes are both a diagnostic test of fine-grained perception and a practical requirement for GUI agents and design tools. We introduce \textbf{DiffSpot}, a code-driven benchmark for open-ended spot-the-difference on web interfaces. DiffSpot constructs controlled image pairs by mutating a single CSS property of a target element in self-contained HTML, re-rendering the page, and recording the changed property, element, and mutation magnitude. A grounding gate retains only pairs whose rendered pixel difference is confined to the target element. The benchmark contains 4{,}400 pairs, including 3{,}900 has-diff pairs balanced across 13 CSS-property operators and three difficulty tiers, plus 500 no-diff pairs for hallucination control. Evaluating 13 frontier VLMs zero-shot, we find that even the best model identifies only $40.7\%$ of true changes, with Hard-tier Recall below $23\%$ for every model. DiffSpot further shows that difficulty is strongly property-dependent: across CSS operators, neither pixel magnitude nor CLIP distance reliably predicts Recall.
Heterogeneous Multi-Agent Modeling for Measurement and Network Analysis of the Data Service Market
May 22, 2026With the increasing complexity of collaboration among various social entities and user demands, the factors affecting the stable development of the data service market are also growing. These factors include the widespread dissemination of information enhancing subjective consciousness, the continuous improvement in intelligence, and the complexification of structural relationships. To achieve effective governance and regulation of the data service market, it is crucial to conduct simulation experiments before making regulatory decisions. However, current research and analysis of the data service market primarily focus on data-level performance, proving inadequate when it comes to measurement and analysis of multiple heterogeneous entities and the integration of various social elements within the data service market. Based on this, this paper innovatively proposes a data service market measurement and network analysis method based on heterogeneous multi-agent modeling. By introducing the service ecosystem theory, we clarify the participants and external factors of the data service market and conduct utility measurements for three-level entities based on value creation. Furthermore, an analytical methodology is devised to precisely assess the influence of heterogeneous networks on utility. Finally, the paper verifies the effectiveness of the proposed method through the analysis of experimental results.
Beyond Transcription: Unified Audio Schema for Perception-Aware AudioLLMs
Apr 14, 2026Recent Audio Large Language Models (AudioLLMs) exhibit a striking performance inversion: while excelling at complex reasoning tasks, they consistently underperform on fine-grained acoustic perception. We attribute this gap to a fundamental limitation of ASR-centric training, which provides precise linguistic targets but implicitly teaches models to suppress paralinguistic cues and acoustic events as noise. To address this, we propose Unified Audio Schema (UAS), a holistic and structured supervision framework that organizes audio information into three explicit components -- Transcription, Paralinguistics, and Non-linguistic Events -- within a unified JSON format. This design achieves comprehensive acoustic coverage without sacrificing the tight audio-text alignment that enables reasoning. We validate the effectiveness of this supervision strategy by applying it to both discrete and continuous AudioLLM architectures. Extensive experiments on MMSU, MMAR, and MMAU demonstrate that UAS-Audio yields consistent improvements, boosting fine-grained perception by 10.9% on MMSU over the same-size state-of-the-art models while preserving robust reasoning capabilities. Our code and model are publicly available at https://github.com/Tencent/Unified_Audio_Schema.
WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference
Dec 28, 2025Autoregressive (AR) generation is the standard decoding paradigm for Large Language Models (LLMs), but its token-by-token nature limits parallelism at inference time. Diffusion Language Models (DLLMs) offer parallel decoding by recovering multiple masked tokens per step; however, in practice they often fail to translate this parallelism into deployment speed gains over optimized AR engines (e.g., vLLM). A key reason is that many DLLMs rely on bidirectional attention, which breaks standard prefix KV caching and forces repeated contextualization, undermining efficiency. We propose WeDLM, a diffusion decoding framework built entirely on standard causal attention to make parallel generation prefix-cache friendly. The core idea is to let each masked position condition on all currently observed tokens while keeping a strict causal mask, achieved by Topological Reordering that moves observed tokens to the physical prefix while preserving their logical positions. Building on this property, we introduce a streaming decoding procedure that continuously commits confident tokens into a growing left-to-right prefix and maintains a fixed parallel workload, avoiding the stop-and-wait behavior common in block diffusion methods. Experiments show that WeDLM preserves the quality of strong AR backbones while delivering substantial speedups, approaching 3x on challenging reasoning benchmarks and up to 10x in low-entropy generation regimes; critically, our comparisons are against AR baselines served by vLLM under matched deployment settings, demonstrating that diffusion-style decoding can outperform an optimized AR engine in practice.
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
Sep 26, 2025



Prevalent semantic speech tokenizers, designed to capture linguistic content, are surprisingly fragile. We find they are not robust to meaning-irrelevant acoustic perturbations; even at high Signal-to-Noise Ratios (SNRs) where speech is perfectly intelligible, their output token sequences can change drastically, increasing the learning burden for downstream LLMs. This instability stems from two flaws: a brittle single-path quantization architecture and a distant training signal indifferent to intermediate token stability. To address this, we introduce StableToken, a tokenizer that achieves stability through a consensus-driven mechanism. Its multi-branch architecture processes audio in parallel, and these representations are merged via a powerful bit-wise voting mechanism to form a single, stable token sequence. StableToken sets a new state-of-the-art in token stability, drastically reducing Unit Edit Distance (UED) under diverse noise conditions. This foundational stability translates directly to downstream benefits, significantly improving the robustness of SpeechLLMs on a variety of tasks.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Apr 03, 2025The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems. To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation. Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights. In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain. More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset. We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
CodeV: Issue Resolving with Visual Data
Dec 23, 2024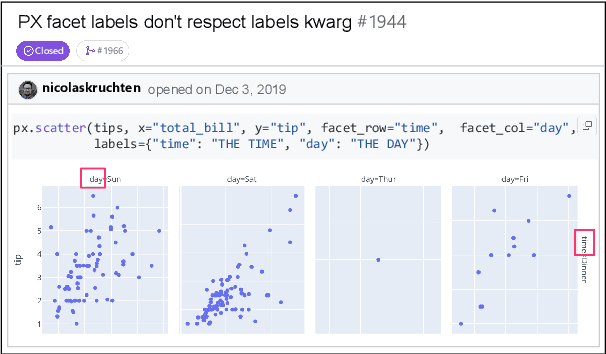
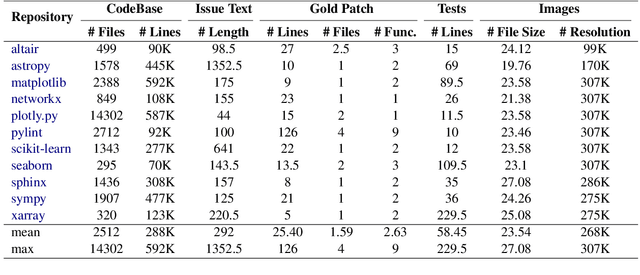


Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.
CoFE-RAG: A Comprehensive Full-chain Evaluation Framework for Retrieval-Augmented Generation with Enhanced Data Diversity
Oct 16, 2024Retrieval-Augmented Generation (RAG) aims to enhance large language models (LLMs) to generate more accurate and reliable answers with the help of the retrieved context from external knowledge sources, thereby reducing the incidence of hallucinations. Despite the advancements, evaluating these systems remains a crucial research area due to the following issues: (1) Limited data diversity: The insufficient diversity of knowledge sources and query types constrains the applicability of RAG systems; (2) Obscure problems location: Existing evaluation methods have difficulty in locating the stage of the RAG pipeline where problems occur; (3) Unstable retrieval evaluation: These methods often fail to effectively assess retrieval performance, particularly when the chunking strategy changes. To tackle these challenges, we propose a Comprehensive Full-chain Evaluation (CoFE-RAG) framework to facilitate thorough evaluation across the entire RAG pipeline, including chunking, retrieval, reranking, and generation. To effectively evaluate the first three phases, we introduce multi-granularity keywords, including coarse-grained and fine-grained keywords, to assess the retrieved context instead of relying on the annotation of golden chunks. Moreover, we release a holistic benchmark dataset tailored for diverse data scenarios covering a wide range of document formats and query types. We demonstrate the utility of the CoFE-RAG framework by conducting experiments to evaluate each stage of RAG systems. Our evaluation method provides unique insights into the effectiveness of RAG systems in handling diverse data scenarios, offering a more nuanced understanding of their capabilities and limitations.
COT: A Generative Approach for Hate Speech Counter-Narratives via Contrastive Optimal Transport
Jun 18, 2024



Counter-narratives, which are direct responses consisting of non-aggressive fact-based arguments, have emerged as a highly effective approach to combat the proliferation of hate speech. Previous methodologies have primarily focused on fine-tuning and post-editing techniques to ensure the fluency of generated contents, while overlooking the critical aspects of individualization and relevance concerning the specific hatred targets, such as LGBT groups, immigrants, etc. This research paper introduces a novel framework based on contrastive optimal transport, which effectively addresses the challenges of maintaining target interaction and promoting diversification in generating counter-narratives. Firstly, an Optimal Transport Kernel (OTK) module is leveraged to incorporate hatred target information in the token representations, in which the comparison pairs are extracted between original and transported features. Secondly, a self-contrastive learning module is employed to address the issue of model degeneration. This module achieves this by generating an anisotropic distribution of token representations. Finally, a target-oriented search method is integrated as an improved decoding strategy to explicitly promote domain relevance and diversification in the inference process. This strategy modifies the model's confidence score by considering both token similarity and target relevance. Quantitative and qualitative experiments have been evaluated on two benchmark datasets, which demonstrate that our proposed model significantly outperforms current methods evaluated by metrics from multiple aspects.